Node与V8
Node
node.js 是什么?
Node.js 是能够在服务器端运行的JavaScript的开放源代码,跨平台运行环境。Node.js采用Google V8 运行代码。
利用事件驱动,非阻塞和异步输入输出模型等技术来提高性能。可优化应用程序的传输量和规模。
术语:
事件驱动:现代系统都是主程序启动完毕后,对每个收到的请求开启一个进程,然后根据不同的技术有不同的处理方式。典型的实现就是:针对一个请求开启一个线程,一步接着一步执行任务操作。如果操作缓慢则后续的操作就会挂起。直到所有操作完成,返回结果。对于Node.js中,所有的操作都注册为一个事件,等待主程序或者外部请求来触发。
运行时:Node.js 运行时是指所有这些代码(上述所有组件,包括底层和上层)提供给 Node.js 应用程序执行的环境
I/O:输入/输入 基本上代指那些主要由计算机 I/O 子系统处理的操作。重 I/O 操作(I/O-bound operations)通常会牵涉到磁盘或驱动器访问,例如数据库访问或文件系统相关操作。它们的区分是根据系统哪部分性能对这个操作有最大的影响。比如对于某项操作而言,CPU 运算能力提高可以带来最大的提升,这项操作就属于重 CPU 操作。
非阻塞/异步:当一项请求发来,应用程序会处理这个请求。其他操作需要等这个请求完成后才能执行。对于这种情况,Node.js采用另一种方式,不再为每个请求开启一个新的线程,而是将所有请求都在单一的主线程中处理。对于其他操作,比如:处理请求–请求中包含的I/O操作文件系统访问,数据库读写等都是转发给libuv管理的工作线程去执行,也就是请求中I/O操作是异步的,并非是主线程上进行。这个方法从而不会导致主线程堵塞。所有耗时的任务处理都分配到其他工作线程中。而我们需要面对的只有唯一主线程。所有libuv管理的工作线程都和唯一主线程隔离开。在这个架构之上重 I/O 操作变得格外高效,那些重 CPU、重内存的也一样。
node的内部结构
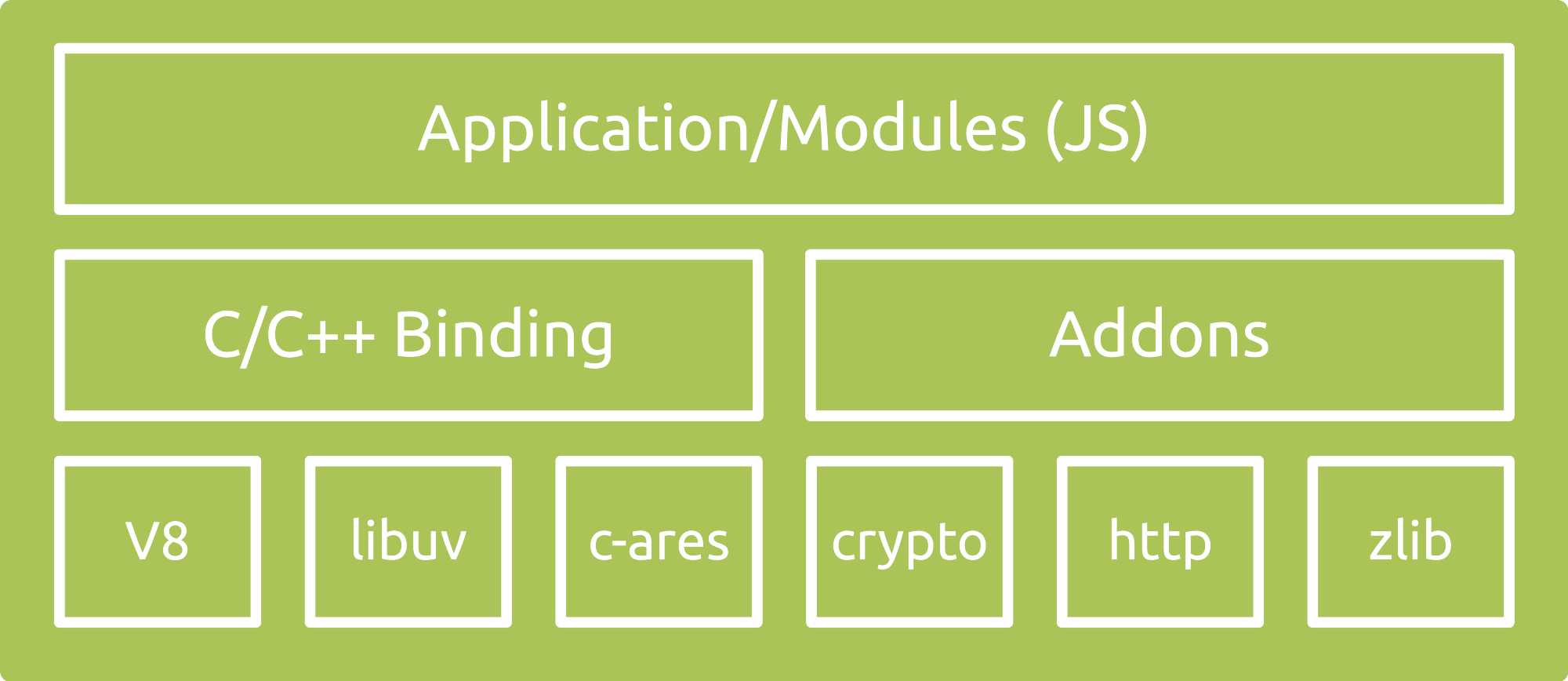
V8: V8是一个开源JavaScript引擎。用C++实现,chrome中集成的JavaScript引擎就是V8引擎。在V8运行之前就会将JavaScript编译成机器代码,而非字节码或者是解释执行它,以提升性能与运行速度。这也是为什么JavaScript程序和V8引擎的速度媲美二进制编译。
(速度有多快)
libuv: 提供异步功能的C库。它在运行时负责一个事件循环(Event Loop),一个线程池 文件系统I/O,DNS相关的网络I/O,以及管理进程相关的函数等一些重要内容。
其他 C/C++ 组件和库:如 c-ares、crypto (OpenSSL)、http-parser 以及 zlib。这些依赖提供了对系统底层功能的访问,包括网络、压缩、加密等。
应用/模块(Application/Modules):所有的JavaScript代码(可以理解为应用层)。JavaScript编写的应用程序,Node.js 核心模块,npm安装的相关依赖包,一节自己写的所有模块代码。
C/C++ Binding(绑定):根据字面意思就可以理解为代码的粘合作用,JavaScript代码如何能与C/C++代码中相互调用,离不开Binding。Binding能够将不同语言并定在一起相互调用。Binding的实现方式就是将Node.js那些C/C++写的库暴露给JavaScript环境中。目的之一就是可以进行代码的复用,无需为了考虑其他语言环境,很多机制与实现已经很成熟,只需要桥接一下就可以了。另外一个就是性能:C/C++ 这样的系统编程语言通常都比其他高阶语言(Python、JavaScript、Ruby 等等)性能更高。所以把主要消耗 CPU 的操作以 C/C++ 代码来执行更加明智
C/C++ Addons:binding仅仅只是起到把上层应用程序与底层核心库(c-ares、crypto (OpenSSL)、http-parser 以及 zlib)桥接作用,但是如果在某些情况下,应用程序会需要第三方或者自己编写的 C/C++ 库的话,那么就需要Addons来将应用程序与第三方库或者自己的的C/C++ 库进行桥接(粘合)
运行机制
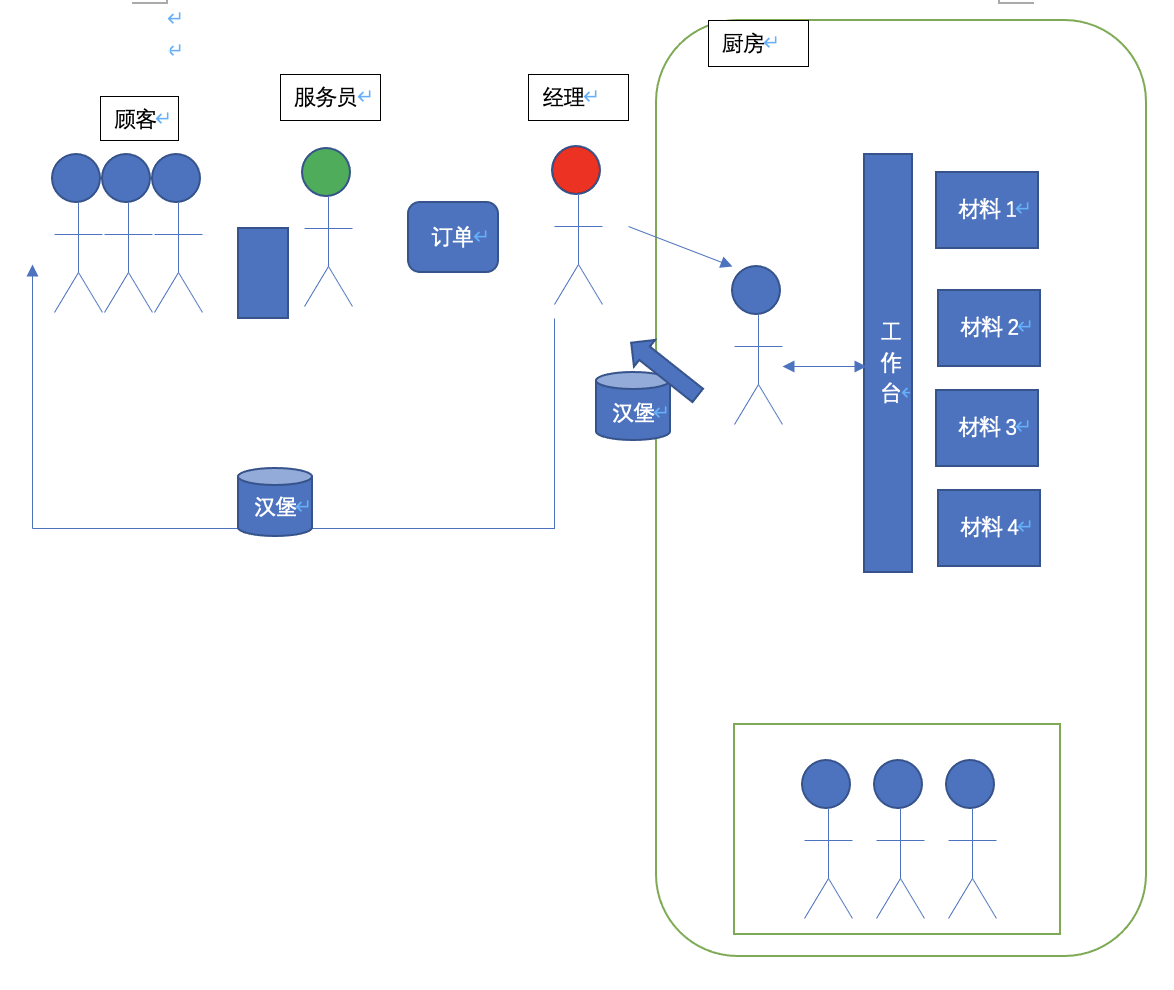
mbq打了一个很有形象的比方:
I have come up with an analogy; web application should be as a restaurant. You have waiters (web server) and cooks (workers). Waiters are in contact with clients and do simple tasks like providing menu or explaining if some dish is vegetarian. On the other hand they delegate harder tasks to the kitchen. Because waiters are doing only simple things they respond quick, and cooks can concentrate on their job.
也可以将Nodejs应用程序比较汉堡店,高水平前台服务员(唯一主线程)在柜台接受订单
- 当有很多顾客到来的的时候,顾客就会排队(进入事件队列)等待接待。
- 每当服务员接待一个顾客的时候,服务员会将订单告诉经理(libuv)。经理会安排相应的专职人员去制作汉堡(工作线程和系统特性)。
- 专职人员会使用不同的材料与机器(底层 C/C++ 组件)按照订单要求制作汉堡。通常会有4个专职人员在岗待命(线程池),订单较多的情况下可以安排更多人(不过需要提前安排,无法进行临时通知)。
- 前台服务员在将订单交给经理后无需等待汉堡制作完成,可以直接接待下一个顾客。(事件循环放到调用堆栈的另一个事件)。你可以把当前调用堆栈里的事件看成是站在柜台前正在接受服务的顾客.
- 当汉堡制作完成后,会发送到顾客队列最后位置。当它移动到柜台前服务员会叫相应顾客名称取餐。
V8
术语:
AST语法树:在计算机科学中,抽象语法树(Abstract Syntax Tree,AST),或简称语法树(Syntax tree),是源代码语法结构的一种抽象表示。它以树状的形式表现编程语言的语法结构,树上的每个节点都表示源代码中的一种结构。
机器码:机器语言(machine language)是一种指令集的体系。这种指令集称为机器代码(machine code),是电脑的CPU可直接解读的资料。
字节码:字节码(英语:Bytecode)通常指的是已经经过编译,但与特定机器代码无关,需要解释器转译后才能成为机器代码的中间代码。字节码通常不像源码一样可以让人阅读,而是编码后的数值常量、引用、指令等构成的序列。
JIT:在计算机技术中,即时编译(英语:just-in-time compilation,缩写为JIT;又译及时编译、实时编译),也称为动态翻译或运行时编译,是一种执行计算机代码的方法,这种方法涉及在程序执行过程中(在运行期)而不是在执行之前进行编译。通常,这包括源代码或更常见的字节码到机器码的转换,然后直接执行。
什么是V8?
v8: 是Google 的开源高性能的由C++编写的JavaScript和webAssembly引擎。它实现了ECMAScript和WebAssembly并在多个不同平台中运行。V8可以独立运行也可以嵌套在任何C++应用程序中。
V8 is Google’s open source high-performance JavaScript and WebAssembly engine, written in C++. It is used in Chrome and in Node.js, among others. It implements ECMAScript and WebAssembly, and runs on Windows 7 or later, macOS 10.12+, and Linux systems that use x64, IA-32, ARM, or MIPS processors. V8 can run standalone, or can be embedded into any C++ application. –v8官网
V8只是JavaScript引擎的一种,常说的JavaScript引擎有很多中:
- JavaScriptCore 代表浏览器Safari
- Rhino 代表浏览器Mozilla Firefox
- Chakra 代表浏览器Internet Explorer(IE)
- V8 代表浏览器 Chrome 开源,用 C++ 实现的
解释器和编译器
- 编译型语言在程序执行之前,需要经过编译器的编译过程,并且编译之后会直接保留机器能读懂的二进制文件,这样每次运行程序时,都可以直接运行该二进制文件,而不需要再次重新编译了。
- 而由解释型语言编写的程序,在每次运行时都需要通过解释器对程序进行动态解释和执行。

大致流程:
- 在编译型语言的编译过程中,编译器首先会依次对源代码进行词法分析、语法分析,生成抽象语法树(AST),然后是优化代码,最后再生成处理器能够理解的机器码。如果编译成功,将会生成一个可执行的文件。但如果编译过程发生了语法或者其他的错误,那么编译器就会抛出异常,最后的二进制文件也不会生成成功。
- 在解释型语言的解释过程中,同样解释器也会对源代码进行词法分析、语法分析,并生成抽象语法树(AST),不过它会再基于抽象语法树生成字节码,最后再根据字节码来执行程序、输出结果。
V8内部中JavaScript执行过程:
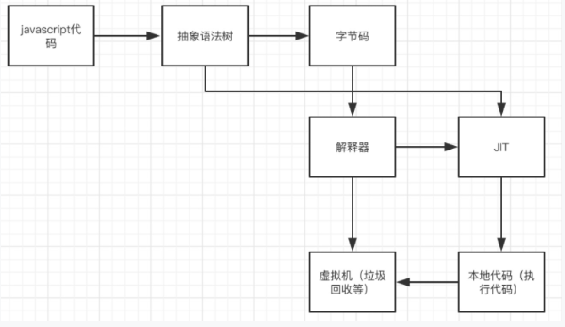
- Js代码转换成AST语法树表示
1 | // 函数 |

AST转换成字节码
之前的V8直接是转换机器码。但是机器码占空间很大,如果v8 缓存机制将 所有 js 代码编译成机器码缓存下来,这样会导致缓存占用的内存、磁盘空间很大。而且退出 Chrome 再打开时序列化、反序列化缓存时间成本也很高。在时间,空间成本都很高的情况下 引入了字节码。字节码解释器
TurboFan内部也存在很多工作内容:
- 字节码处理程序生成
- 字节码生成
- 解释器寄存器分配
- Context链
- 异常处理
- JS代码解释执行
JIT (Just In Time) 混合使用编译器和解释器的技术。编译器启动速度慢,执行速度快。解释器的启动速度快,执行速度慢。而JIT技术就是取俩者之长 (Ignition(字节码解释器) + TurboFan (JIT编译器) 的组合;
虚拟机(垃圾回收,内存管理等)

V8 使用了分代和大数据的内存分配,在回收内存时使用精简整理的算法标记未引用的对象,然后消除没有标记的对象,最后整理和压缩那些还未保存的对象,即可完成垃圾回收。
内存分配:
- 年轻分代:为新创建的对象分配内存空间,经常需要进行垃圾回收。为方便年轻分代中的内容回收,可再将年轻分代分为两半,一半用来分配,另一半在回收时负责将之前还需要保留的对象复制过来。
- 年老分代:根据需要将年老的对象、指针、代码等数据保存起来,较少地进行垃圾回收。
- 大对象:为那些需要使用较多内存对象分配内存,当然同样可能包含数据和代码等分配的内存,一个页面只分配一个对象。
内存(垃圾)回收:
- 年轻分代中的对象垃圾回收主要通过Scavenge算法进行垃圾回收。
- 因考虑在年老分代中存活对象居多,所以主要采用了Mark-Sweep(标记清除)标记清除和Mark-Compact(标记整理)相结合的方式进行垃圾回收。
V8引擎的内部结构
V8是一个很复杂的项目,它有很多子模块构成,其中有4个模块尤为重要:
Parser:负责将 JavaScript 源码转换为 Abstract Syntax Tree (AST)
确切的说,在“Parser”将 JavaScript 源码转换为 AST前,还有一个叫”Scanner“的过程,具体流程如下:
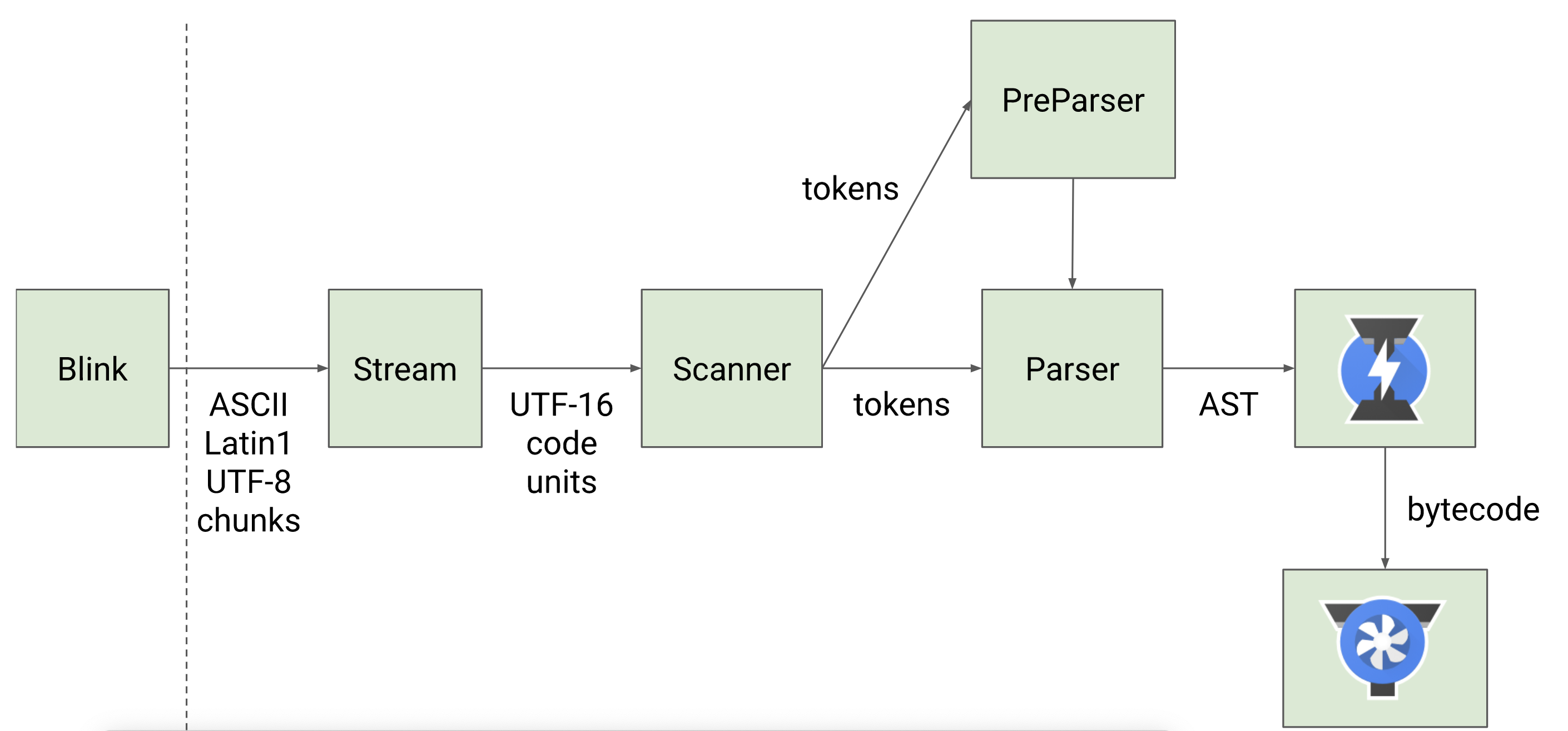
Ignition:interpreter,即解释器,负责将 AST 转换为 Bytecode,解释执行 Bytecode;同时收集 TurboFan 优化编译所需的信息,比如函数参数的类型;解释器执行时主要有四个模块,内存中的字节码、寄存器、栈、堆.
通常有两种类型的解释器,基于栈 (Stack-based)和基于寄存器 (Register-based),基于栈的解释器使用栈来保存函数参数、中间运算结果、变量等;基于寄存器的虚拟机则支持寄存器的指令操作,使用寄存器来保存参数、中间计算结果。通常,基于栈的虚拟机也定义了少量的寄存器,基于寄存器的虚拟机也有堆栈,其区别体现在它们提供的指令集体系。大多数解释器都是基于栈的,比如 Java 虚拟机,.Net 虚拟机,还有早期的 V8 虚拟机。基于堆栈的虚拟机在处理函数调用、解决递归问题和切换上下文时简单明快。而现在的 V8 虚拟机则采用了基于寄存器的设计,它将一些中间数据保存到寄存器中。
基于寄存器的解释器架构: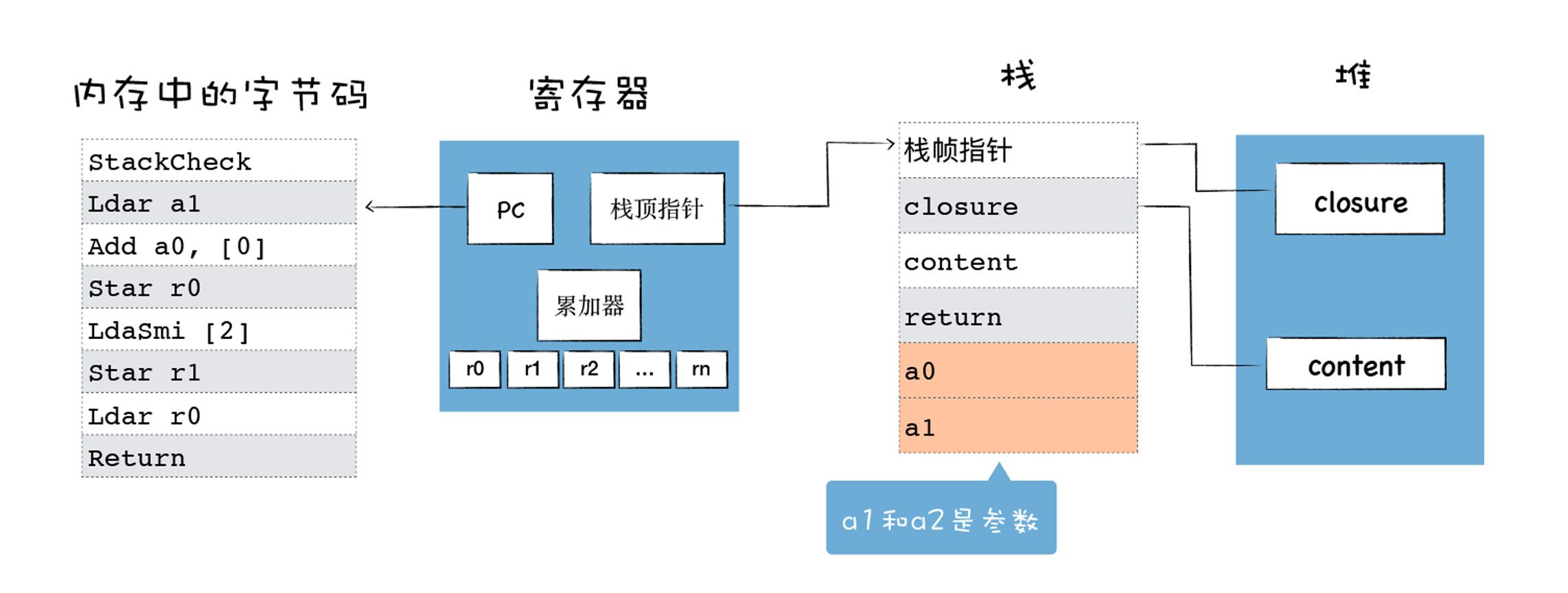
资料参考:解释器是如何解释执行字节码的?TurboFan:compiler,即编译器,利用 Ignition 所收集的类型信息,将 Bytecode 转换为优化的汇编代码;
Orinoco:garbage collector,垃圾回收模块,负责将程序不再需要的内存空间回收
Parser,Ignition 以及 TurboFan 可以将 JS 源码编译为汇编代码,其流程图如下: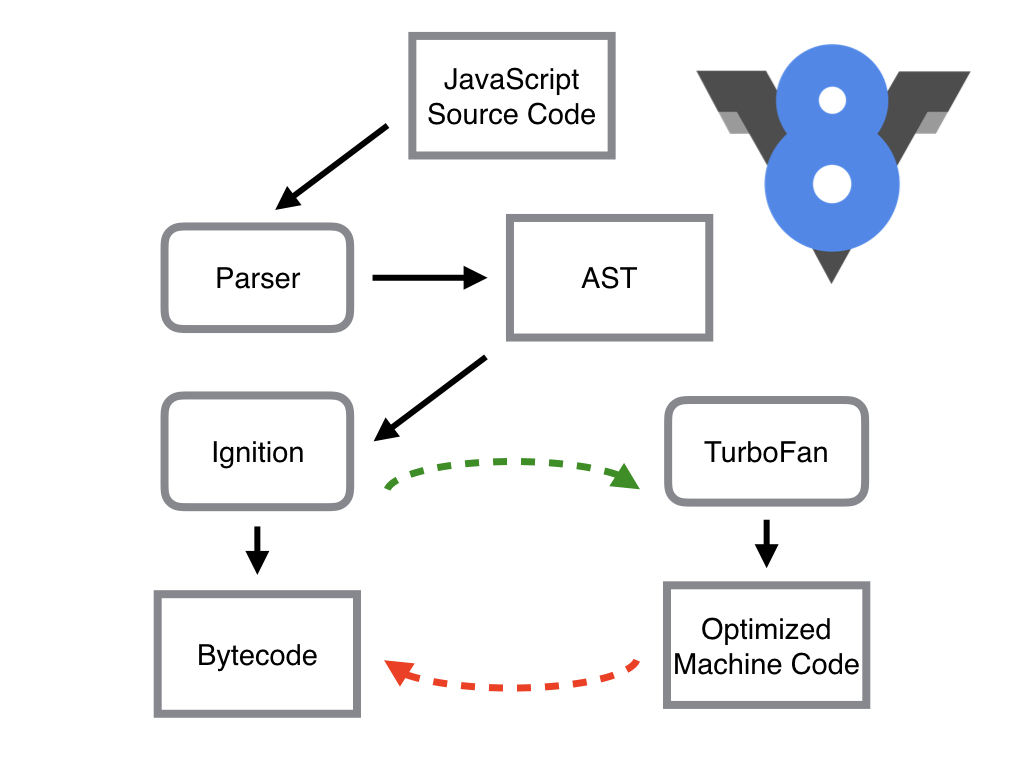
简单地说,Parser 将 JS 源码转换为 AST,然后 Ignition 将 AST 转换为 Bytecode,最后 TurboFan 将 Bytecode 转换为经过优化的 Machine Code(实际上是汇编代码)。
- 如果函数没有被调用,则 V8 不会去编译它。
- 如果函数只被调用 1 次,则 Ignition 将其编译 Bytecode 就直接解释执行了。TurboFan 不会进行优化编译,因为它需要 Ignition 收集函数执行时的类型信息。这就要求函数至少需要执行 1 次,TurboFan 才有可能进行优化编译。
- 如果函数被调用多次,则它有可能会被识别为热点函数,且 Ignition 收集的类型信息证明可以进行优化编译的话,这时 TurboFan 则会将 Bytecode 编译为 Optimized Machine Code(已优化的机器码),以提高代码的执行性能。
图片中的红色虚线是逆向的,也就是说 Optimized Machine Code 会被还原为 Bytecode,这个过程叫做 Deoptimization。这是因为 Ignition 收集的信息可能是错误的,比如 add 函数的参数之前是整数,后来又变成了字符串。生成的 Optimized Machine Code 已经假定 add 函数的参数是整数,那当然是错误的,于是需要进行 Deoptimization。
1 | function add(x, y) { |
在运行 C、C++以及 Java 等程序之前,需要进行编译,不能直接执行源码;但对于 JavaScript 来说,我们可以直接执行源码(比如:node test.js),它是在运行的时候先编译再执行,这种方式被称为即时编译(Just-in-time compilation),简称为 JIT。因此,V8 也属于 JIT 编译器。
资料拓展参考:V8 引擎是如何工作的?