Jest
介绍
Facebook 开源的一套 JavaScript 测试框架,它集成了断言库、mock、快照测试、覆盖率报告等功能。它非常适合用来测试 React 代码,但不仅仅如此,所有的 js 代码都可以使用 Jest 进行测试
快照测试
快照测试的基本理念,即:先保存一份副本文件,下次测试时把当前输出和上次副本文件对比就知道此次重构是否破坏了某些东西。
jest 的快照测试提供了更高级的功能:
- 自动创建把输出内容写到 .snap 快照文件,下次测试时可以自动对比
- 输出格式化的快照文件,阅读友好,开发者更容易看懂
- 当在做 diff 对比时,jest 能高亮差异点,而且对比信息更容易阅读
1 | // tests/components/Title.test.tsx |
执行测试后,会发现在 tests/components/ 下多了一个 Title.test.tsx.snap 文件,打开来看看:
1 | // tests/components/Title.test.tsx.snap |
快照测试通过说明渲染组件没有变,如果不通过则有两种可能:
- 代码有 Bug。 本来好好的,被你这么一改,改出了问题
- 实现了新功能。 新功能可能会改变原有的 DOM 结构,所以你要用 jest –updateSnapshot 来更新快照
缺陷
- 避免大快照
真实业务组件中动辄就有十几个标签,还带上很多乱七八糟的属性,生成的快照文件会变得无比巨大。
对于这个问题,我们能做的就是避免大快照,不要无脑地记录整个组件的快照,特别是有别的 UI 组件参与其中的时候:
1 | const Title: FC<Props> = (props) => { |
对于那种输出很复杂,而且不方便用 expect 做断言时,快照测试才算是一个好方法。 这也是为什么组件 DOM 结构适合做快照,因为 DOM 结构有大量的大于、小于、引号这些字符。如果都用 expect 来断言,expect 的结果会写得非常痛苦。 不过,需要注意的是:不要把无关的 DOM 也记录到快照里,这无法让人看懂。
- 假错误
业务代码并没有任何问题,测试却出错了,这就是测试中的 “假错误”
1 | describe("Title", () => { |
在一些大快照,复杂组件的情况下,只要别的开发者改了某个地方,很容易导致一大片快照报错,基于人性的弱点,他们是没耐心看测试失败的原因的, 再加上更新快照的成本很低,只要加个 –updateSnapshot 就可以了,所以人们在面对快照测试不通过时,往往选择更新快照而不去思考 DOM 结构是否真的变了。
这些因素造成的最终结果就是:不再信任快照测试。 所以,你也会发现市面上很多前端测试的总结以及文章都很少做 快照测试。很大原因是快照测试本身比较脆弱, 而且容易造成 “假错误”。
- 快照的扩展
把快照测试直接等于组件的 UI 测试,或者说快照测试是只用来测组件的。而事实上并不是! Jest 的快照可不仅仅能记录 DOM 结构,还能记录 一切能被序列化 的内容,比如纯文本、JSON、XML 等等。
总结
快照测试。快照测试的思想很简单:
- 先执行一次测试,把输出结果记录到 .snap 文件,以后每次测试都会把输出结果和 .snap 文件做 对比
- 快照失败有两种可能:
- 业务代码变更后导致输出结果和以前记录的 .snap 不一致,说明业务代码有问题,要排查 Bug
- 业务代码有更新导致输出结果和以前记录的 .snap 不一致,新增功能改变了原有的 DOM 结构,要用
npx jest --updateSnapshot更新当前快照
要避免“假错误”的情况,需要做好两点:
- 生成小快照。 只取重要的部分来生成快照,必须保证快照是能让你看懂的
- 合理使用快照。 快照测试不是只为组件测试服务,同样组件测试也不一定要包含快照测试。快照能存放一切可序列化的内容。
根据上面两点,还能总结出快照测试的适用场景:
- 组件 DOM 结构的对比
- 在线上跑了很久的老项目
- 大块数据结果的对比
组件测试
大多数情况下,对于组件中都会参杂对后端 API 的调用,但是对于每次测试来说不可能时刻调用后端接口。这个时候就需要利用 jest mock 功能 mock 后端请求返回值。
1 | // src/components/AuthButton/index.tsx |
Mock Axios
1 | // tests/components/AuthButton/mockAxios.test.tsx |
分别对两个用例的 axios.get 进行了 Mock,使得一个 Mock 返回 user,另一个 Mock 返回 admin。 最后,在这两个用例里分别断言 <AuthButton/> 的渲染内容。
Mock API 函数
1 | // tests/components/AuthButton/mockGetUserRole.test.tsx |
和第一种方法类似,我们依然监听了某个函数(这里是 getUserRole),通过 Mock 其返回来模拟不同场景。
Mock Http
我们可以不 Mock 任何函数实现,只对 Http 请求进行 Mock! 这个时候我们需要安装msw
msw可以拦截指定的 Http 请求,有点类似 Mock.js,是做测试时一个非常强大好用的 Http Mock 工具。
1 | npm i -D msw@0.39.2 |
先在 tests/mockServer/handlers.ts 里添加 Http 请求的 Mock Handler:
1 | import { rest } from "msw"; |
然后在 tests/mockServer/server.ts 里使用这些 handlers 创建 Mock Server 并导出它:
1 | import { setupServer } from "msw/node"; |
最后,在我们的 tests/jest-setup.ts 里使用 Mock Server:
1 | import server from "./mockServer/server"; |
这样一来,在所有测试用例中都能获得 handlers.ts 里的 Mock 返回了。如果你想在某个测试文件中想单独指定某个接口的 Mock 返回, 可以使用 server.use(mockHandler) 来实现。 我们以 <AuthButton/> 为例:
1 | // tests/components/AuthButton/mockHttp.test.tsx |
这里声明了一个 setup 函数,用于在每个用例前初始化 Http 请求的 Mock 返回。通过传不同值给 setup 就可以灵活模拟测试场景了。
如何取舍
无论后端测试也好、前端测试也好,不管你要测什么,测试的目的都是为了让你能对测过的代码充满信心(Confidence)。什么样的测试才能提高代码自信呢?很简单:像真实用户那样去测你的代码。
Jest 性能优化
Jest 架构
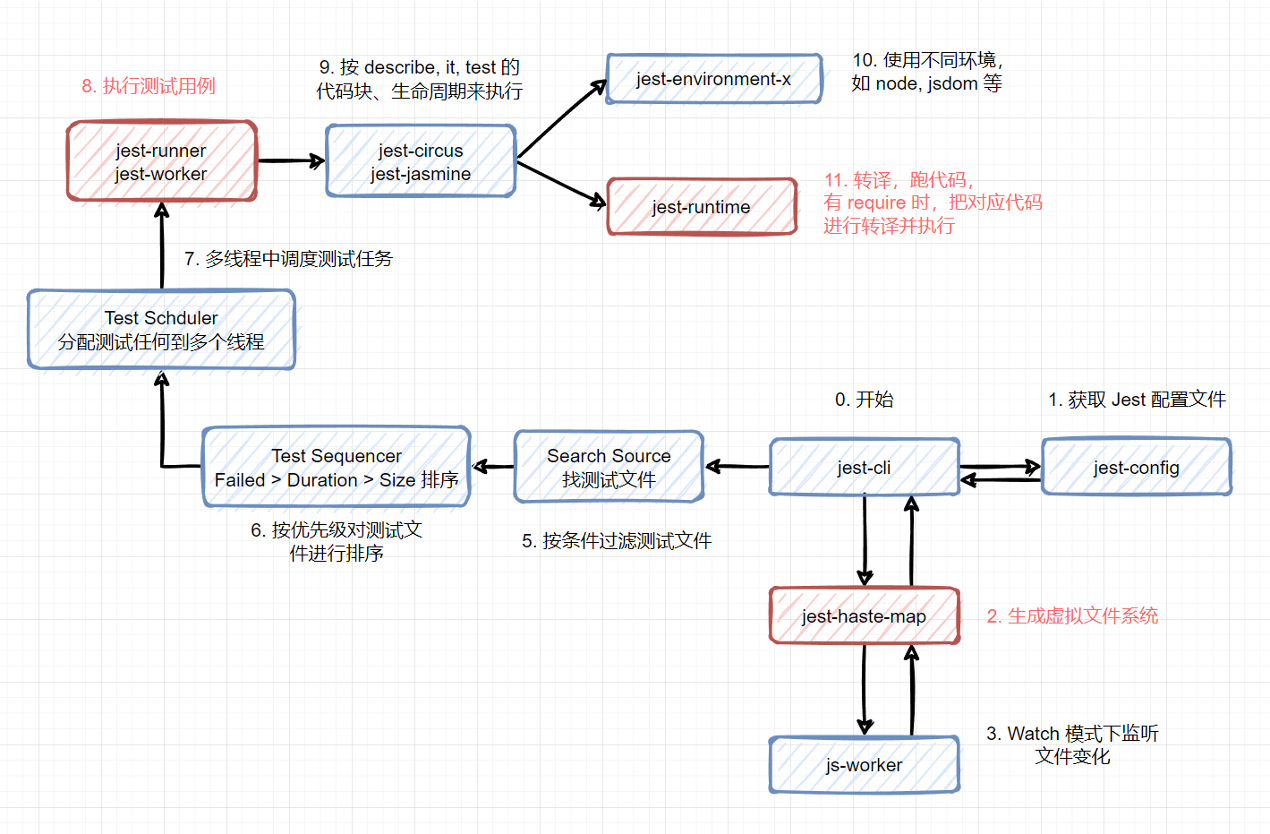
最影响 Jest 性能的有 3 个地方:
- 使用 jest-haste-map 生成虚拟文件系统
- 多线程执行测试任务
- 转译 JavaScript 代码
虚拟文件系统
如果要在热更新时修改文件,脚手架都要遍历一次项目文件,非常损耗性能。特别在一些文件特别多的巨石应用中,电脑分分钟就卡得动不了。
为了解决这个问题,Facebook 团队就想到了一个方法 —— 虚拟文件系统。原理很简单:在第一次启动时遍历整个项目,把文件存储成 Map 的形式, 之后文件做了改动,那么只需增量地修改这个 Map 就可以了。 他们把这个工具命名为 Haste Map,中文翻译可以理解为快速生成 Map 的东西(这名字真的不好)。
这种思路不仅可以用于热更新场景,还能应用在所有监听文件改动的场景,其中一种就是 npx jest –watch 这个场景。
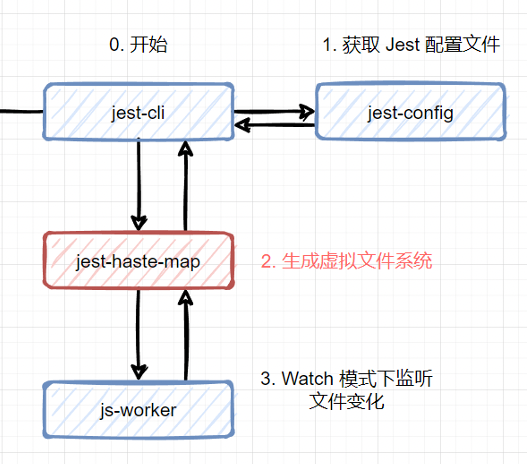
因此,上面图中刚开始时,Jest 就用 jest-haste-map 生成了一次虚拟文件系统,这样后续的过滤、搜索文件就非常快速了。这也是为什么执行第一个测试用例时速度比较慢的原因。 这一步的性能我们无法优化。
多线程
Jest 还有一个非常强大的功能,利用 Node.js 的 Worker 开启多个线程来执行测试用例。对于一些大型项目(几千个测试用例)来说,这能提升不少效率。
但线程不是越多越好,每开一个线程都需要额外的开销。如果不做任何配置,那么 Jest 默认最大的 Worker 数是 CPU 数 - 1。其中的 1 用于运行 jest-cli, 剩下的都拿来执行测试用例。由于之前我们一直没有对 maxWorkers 进行配置,所以默认会用最多的 Worker,执行这么几十个简单的测试会非常慢。
通常来说,单个测试用例速度应该要做到非常快的,尽量不写一些耗时的操作,比如不要加 setTimeout,n 个 for 循环等。 所以,理论上,测试数量不多的情况下单线程就足够了。这里我们可以把 jest.config.js 配置改为用单线程:
1 | // jest.config.js |
在流水线中,Jest 也推荐使用单线程来跑单测和集成测试:jest –runInBand,其中 runInBand 和 maxWorkers: 1 效果是一样的。
在以前的 Intel Mac 里单线程的速度比多线程快了一倍,而 M1 的 Mac 上则是相反,多线程比单线程快。所以,还是要自己的机器的情况来决定使用多少个 Worker。
M1 Macbook Pro,单线程: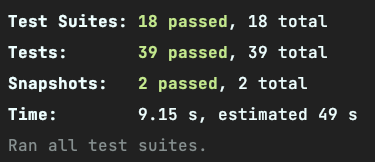
M1 Macbook Pro,多线程: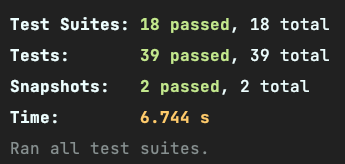
文件转译
最后一个性能优化点就是转译速度(图中第 11 步)。需要注意的是 Jest 是会边执行测试用例边转译 JavaScript
![]()
既然 Jest 刚开始遍历项目来生成虚拟文件系统,为什么不顺便把转译的工作做了呢?
当然是因为慢了。 首先,对于很多业务项目来说,测试并不会很多。可能就测几个 utils 下的函数,那如果把项目的文件都转译一次,会把很多没用到测试的业务代码也转译。
所以说,通过文件找依赖的方式不是很可靠,有太多不确定因素,最终 Jest 还是选择 “执行到那个文件再做转译” 的方法。
原理说完了,下面来看看怎么提高转译效率。在前面的章节里,我们说到当今 JavaScript 的转译器有很多种,不仅可以用 tsc 和 babel 来转, 还能用别的语言写的转译器 swc 以及 esbuild 来转。
如果想用 esbuild 做转译,可以看 esbuild-jest (opens new window)这个库。这里我用 @swc/jest (opens new window)做例子, 先安装依赖:
1 | npm i -D @swc/core@1.2.165 @swc/jest@0.2.20 |
然后在 jest.config.js 里添加:
1 | module.exports = { |
大功告成,配置非常简单,我们来看看使用 ts-jest 以及 @swc/jest 两者的对比。
ts-jest: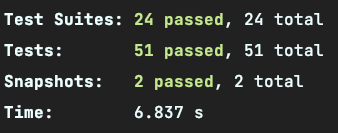
@swc/jest:
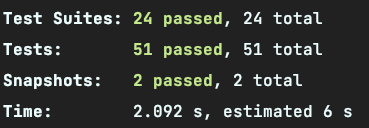
总结
有 3 个地方比较耗性能:
- 生成虚拟文件系统。 在执行第一个测试会很慢
- 多线程。 生成新线程耗费的资源,不过,不同机器的效果会不一致
- 文件转译。 Jest 会在执行到该文件再对它进行转译
解决的方法有:
- 无解,有条件的话拆解项目吧
- 具体情况具体分析,要看机器的执行情况,多线程快就用多线程,单线程快就用单线程
- 使用 esbuild-jest、 @swc/jest 等其它高效的转译工具来做转译